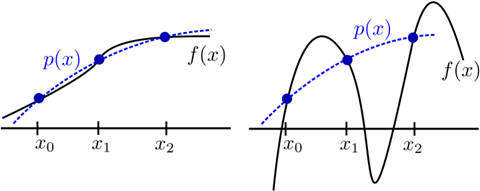
插值的是通过已知数据点构建新数据点的过程。其目标是找到一个函数,该函数在给定的数据点处精确匹配这些点,然后用这个函数来估计未知点的值。插值函数会精确通过所有已知数据点,但可能会在数据点之间出现过度摆动(尤其是在使用高阶多项式插值时)。
考虑一组 点 ( x , y ) (x, y) ( x , y )
( x 0 , y 0 ) , ( x 1 , y 1 ) , … , ( x n , y n ) . (x_0,y_0),\:(x_1,y_1),\:\ldots,\:(x_n,y_n).
( x 0 , y 0 ) , ( x 1 , y 1 ) , … , ( x n , y n ) .
x x x y y y f f f
y i = f ( x i ) y_i=f(x_i)
y i = f ( x i )
图1:三个横坐标 ( x 0 , x 1 , x 2 ) (x_0,x_1,x_2) ( x 0 , x 1 , x 2 ) f ( x ) f(x) f ( x ) p ( x ) p(x) p ( x ) f ( x ) f(x) f ( x )
多项式插值,简单来说,就是找一条曲线(我们称之为多项式),让它恰好穿过我们预先指定的几个点。假设我们有 n + 1 n+1 n + 1 ( x 0 , y 0 ) , … , ( x n , y n ) (x_0,y_0),\dots,(x_n,y_n) ( x 0 , y 0 ) , … , ( x n , y n )
那么,我们的目标就是找到一个恰当的多项式 p p p x i x_i x i p p p y i y_i y i
这里有两个重要的保证:
唯一性 :如果你找到了这样一条曲线(多项式),那么它是独一无二的。这意味着在相同条件下,你不可能找到另一条完全不同的曲线也能穿过所有这些点。
存在性 :无论你给定的点是什么样的,你总能找到这样一条多项式曲线。也就是说,这样的曲线总是存在的。
虽然我们可以用不同的方法来找到这条曲线,但不管用哪一种方法,最终得到的曲线(或者说多项式)都是一样的。这就意味着,所有方法都会指向同一个答案,即那条唯一的、能够穿过所有给定点的多项式曲线。
当我们处理多项式 p p p ϕ 0 , ⋯ , ϕ n \phi_0, \cdots, \phi_n ϕ 0 , ⋯ , ϕ n p p p c i c_i c i
p = c 0 ϕ 0 + c 1 ϕ 1 + ⋯ + c n ϕ n . p = c_0\phi_0 + c_1\phi_1 + \cdots + c_n\phi_n.
p = c 0 ϕ 0 + c 1 ϕ 1 + ⋯ + c n ϕ n .
要想让这个多项式真正符合我们的需要(也就是通过我们指定的点),我们需要找到恰当的系数 c i c_i c i ( x i , y i ) (x_i, y_i) ( x i , y i ) x i x_i x i y i y_i y i n + 1 n+1 n + 1 n + 1 n+1 n + 1
当然,为了让这个过程在实际中更加可行,我们需要选取一些特别的基函数 ϕ i \phi_i ϕ i p p p
构建起来相对容易。
计算系数 c i c_i c i
在数值计算中相对稳定,不会因为小小的计算误差就导致结果大相径庭。
一旦找到了系数 c i c_i c i ϕ i \phi_i ϕ i p ( x ) p(x) p ( x )
这些基函数具有一定的灵活性,能适应数据的微小变化。
最直接、最简单的基函数选择就是单项式集合,即让 ϕ i \phi_i ϕ i x i x^i x i
p ( x ) = c 0 + c 1 x + ⋯ + c n x n . p(x) = c_0 + c_1x + \cdots + c_nx^n.
p ( x ) = c 0 + c 1 x + ⋯ + c n x n .
用这种方法可以建立一个方程组并求解:
如果给定 n n n ( x i , y i ) , i = 1 , 2 , … , n (x_i,y_i),i=1,2,\ldots,n ( x i , y i ) , i = 1 , 2 , … , n
p ( x ) = ∑ i = 0 n − 1 c i x i p(x)=\sum_{i=0}^{n-1}c_i\:x^i
p ( x ) = i = 0 ∑ n − 1 c i x i
根据构造条件,有
{ p ( x 1 ) = y 1 p ( x 2 ) = y 2 ⋯ p ( x n ) = y n \begin{cases}p(x_1)=y_1\\p(x_2)=y_2\\\cdots\\p(x_n)=y_n\end{cases}
⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ p ( x 1 ) = y 1 p ( x 2 ) = y 2 ⋯ p ( x n ) = y n
将上述线性方程组中的c i , i = 1 , 2 , … , n c_i,i=1,2,\ldots,n c i , i = 1 , 2 , … , n A A A
V ( x 1 , x 2 , ⋯ , x n ) = [ 1 1 ⋯ 1 x 1 x 2 ⋯ x n x 1 2 x 2 2 ⋯ x n 2 ⋮ ⋮ ⋮ x 1 n − 1 x 2 n − 1 ⋯ x n n − 1 ] V(x_1,x_2,\cdots,x_n)=\begin{bmatrix}1&1&\cdots&1\\x_1&x_2&\cdots&x_n\\x_1^2&x_2^2&\cdots&x_n^2\\\vdots&\vdots&&\vdots\\x_1^{n-1}&x_2^{n-1}&\cdots&x_n^{n-1}\end{bmatrix}
V ( x 1 , x 2 , ⋯ , x n ) = ⎣ ⎢ ⎢ ⎢ ⎢ ⎢ ⎢ ⎡ 1 x 1 x 1 2 ⋮ x 1 n − 1 1 x 2 x 2 2 ⋮ x 2 n − 1 ⋯ ⋯ ⋯ ⋯ 1 x n x n 2 ⋮ x n n − 1 ⎦ ⎥ ⎥ ⎥ ⎥ ⎥ ⎥ ⎤
故(数学归纳法证明)
d e t ( A ) = ∏ 1 ≤ i < j ≤ n ( x j − x i ) det(A)=\prod_{1\leq i<j\leq n}(x_j-x_i)
d e t ( A ) = 1 ≤ i < j ≤ n ∏ ( x j − x i )
又x i x_i x i i = 1 , 2 , … , n i=1,2,\ldots,n i = 1 , 2 , … , n d e t ( A ) ≠ 0 det(A)\neq0 d e t ( A ) = 0
令:
{ y 0 = α 0 + α 1 x 0 + α 2 x 0 2 + ⋯ + α n x 0 n y 1 = α 0 + α 1 x 1 + α 2 x 1 2 + ⋯ + α n x 1 n ⋮ y n = α 0 + α 1 x n + α 2 x n 2 + ⋯ + α n x n n \left\{\begin{array}{ccc}y_0&=&\alpha_0+\alpha_1x_0+\alpha_2x_0^2+\cdots+\alpha_nx_0^n\\y_1&=&\alpha_0+\alpha_1x_1+\alpha_2x_1^2+\cdots+\alpha_nx_1^n\\&&\vdots\\y_n&=&\alpha_0+\alpha_1x_n+\alpha_2x_n^2+\cdots+\alpha_nx_n^n\end{array}\right.
⎩ ⎪ ⎪ ⎪ ⎪ ⎨ ⎪ ⎪ ⎪ ⎪ ⎧ y 0 y 1 y n = = = α 0 + α 1 x 0 + α 2 x 0 2 + ⋯ + α n x 0 n α 0 + α 1 x 1 + α 2 x 1 2 + ⋯ + α n x 1 n ⋮ α 0 + α 1 x n + α 2 x n 2 + ⋯ + α n x n n
Y = [ y 0 y 1 ⋮ y n ] , B = [ 1 x 0 x 0 2 … x 0 n 1 x 1 x 1 2 … x 1 n ⋮ ⋮ ⋮ ⋱ ⋮ 1 x n x n 2 … x n n ] , α = [ α 0 α 1 ⋮ α n ] \mathbf{Y}=\left[\begin{array}{c}y_0\\y_1\\\vdots\\y_n\end{array}\right],\quad\mathbf{B}=\left[\begin{array}{ccccc}1&x_0&x_0^2&\ldots&x_0^n\\1&x_1&x_1^2&\ldots&x_1^n\\\vdots&\vdots&\vdots&\ddots&\vdots\\1&x_n&x_n^2&\ldots&x_n^n\end{array}\right],\quad\mathbf{\alpha}=\left[\begin{array}{c}\alpha_0\\\alpha_1\\\vdots\\\alpha_n\end{array}\right]
Y = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ y 0 y 1 ⋮ y n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , B = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ 1 1 ⋮ 1 x 0 x 1 ⋮ x n x 0 2 x 1 2 ⋮ x n 2 … … ⋱ … x 0 n x 1 n ⋮ x n n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤ , α = ⎣ ⎢ ⎢ ⎢ ⎢ ⎡ α 0 α 1 ⋮ α n ⎦ ⎥ ⎥ ⎥ ⎥ ⎤
即:通过求解关于 α \alpha α Y = B α \mathbf{Y}=\mathbf{B}\alpha Y = B α n n n
p ( x ) = α 0 + α 1 x + α 2 x 2 + ⋯ + α n x n p(x)=\alpha_0+\alpha_1x+\alpha_2x^2+\cdots+\alpha_nx^n
p ( x ) = α 0 + α 1 x + α 2 x 2 + ⋯ + α n x n
尽管这个方程组的解法并不总是最理想的。对于较小的 n n n n n n
假设我们希望构造一个多项式 p ( x ) p(x) p ( x ) c i c_i c i
p ( x ) = y 0 L 0 ( x ) + ⋯ + y n L n ( x ) p(x) = y_0L_0(x) + \cdots + y_nL_n(x)
p ( x ) = y 0 L 0 ( x ) + ⋯ + y n L n ( x )
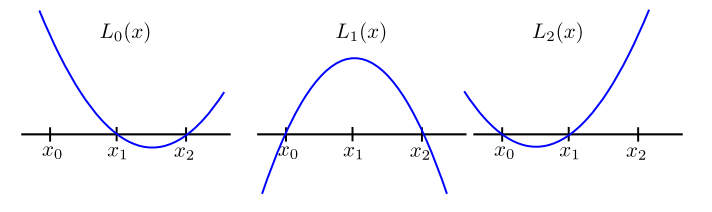
这里的 L 0 , ⋯ , L n L_0, \cdots, L_n L 0 , ⋯ , L n L i L_i L i y i y_i y i
要构建这样的拉格朗日形式,我们需要找到一组特殊的多项式 L i L_i L i
每个 L i L_i L i n n n n n n
对于每个 i i i L i L_i L i x i x_i x i
同时,对于不等于 i i i j j j L i L_i L i x j x_j x j
为了满足这些条件,我们可以构造一种特殊形式的多项式,它在除 x i x_i x i x j x_j x j
L i ( x ) = ∏ j ≠ i x − x j x i − x j . L_i(x) = \prod_{j \neq i} \frac{x - x_j}{x_i - x_j}.
L i ( x ) = j = i ∏ x i − x j x − x j .
这样构造的 L i L_i L i
根据这些基础函数 L i L_i L i ( x 0 , y 0 ) , ⋯ , ( x n , y n ) (x_0, y_0), \cdots, (x_n, y_n) ( x 0 , y 0 ) , ⋯ , ( x n , y n )
p ( x ) = ∑ i = 0 n y i L i ( x ) . p(x) = \sum_{i=0}^n y_iL_i(x).
p ( x ) = i = 0 ∑ n y i L i ( x ) .
这个结论是由 L i L_i L i p p p n n n
举个例子,在线性情况下,我们可以通过两个点 ( x 0 , y 0 ) (x_0, y_0) ( x 0 , y 0 ) ( x 1 , y 1 ) (x_1, y_1) ( x 1 , y 1 )
不过,需要注意的是,尽管拉格朗日形式在理论上很有吸引力,并且在函数值的表示上非常自然,但在实际计算中,计算 L i L_i L i
1 Tips:尽管拉格朗日形式的直接计算可能不是特别高效,但有一些方法可以用来更高效地构造和评估这种形式的多项式。例如,有一种称为重心公式的方法,可以用来高效地计算拉格朗日形式的多项式。
以一个具体的例子来说明如何构建插值多项式。假设我们有以下三个数据点:
x i y i 0 − 1 1 / 2 2 / 3 1 8 / 9 \begin{array}{c|c}
x_i & y_i \\
\hline
0 & -1 \\
1/2 & 2/3 \\
1 & 8/9 \\
\end{array}
x i 0 1 / 2 1 y i − 1 2 / 3 8 / 9
我们的目标是找到一个多项式,它不仅与这些数据点完美吻合,而且其形式尽可能简单。为此,我们采用拉格朗日插值法。下面是根据这些点构建的拉格朗日基础多项式:
对于 x 0 = 0 x_0 = 0 x 0 = 0
L 0 ( x ) = ( x − x 1 ) ( x − x 2 ) ( x 0 − x 1 ) ( x 0 − x 2 ) = 2 ( x − 1 2 ) ( x − 1 ) L_0(x) = \frac{(x-x_1)(x-x_2)}{(x_0-x_1)(x_0-x_2)} = 2(x-\frac{1}{2})(x-1)
L 0 ( x ) = ( x 0 − x 1 ) ( x 0 − x 2 ) ( x − x 1 ) ( x − x 2 ) = 2 ( x − 2 1 ) ( x − 1 )
对于 x 1 = 1 2 x_1 = \frac{1}{2} x 1 = 2 1
L 1 ( x ) = − 4 x ( x − 1 ) L_1(x) = -4x(x-1)
L 1 ( x ) = − 4 x ( x − 1 )
对于 x 2 = 1 x_2 = 1 x 2 = 1
L 2 ( x ) = 2 x ( x − 1 2 ) L_2(x) = 2x(x-\frac{1}{2})
L 2 ( x ) = 2 x ( x − 2 1 )
这些基础多项式帮助我们构建了一个多项式 p ( x ) p(x) p ( x )
p ( x ) = − 2 ( x − 1 2 ) ( x − 1 ) − 2 3 x ( x − 1 ) + 16 9 x ( x − 1 2 ) p(x) = -2(x-\frac{1}{2})(x-1) - \frac{2}{3}x(x-1) + \frac{16}{9}x(x-\frac{1}{2})
p ( x ) = − 2 ( x − 2 1 ) ( x − 1 ) − 3 2 x ( x − 1 ) + 9 1 6 x ( x − 2 1 )
这就是我们通过给定数据点构建的唯一的二次多项式。
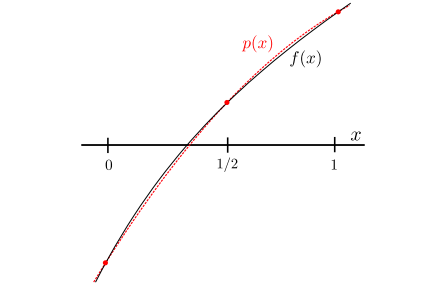
为了直观展示,我们在图中展示了这些基础多项式以及它们构成的插值多项式。
函数 f ( x ) f(x) f ( x ) p ( x ) p(x) p ( x )
结果表明,尽管我们只有三个数据点,但构建的插值多项式与原始函数 f ( x ) = x − 9 − x f(x) = x - 9^{-x} f ( x ) = x − 9 − x
牛顿插值多项式的核心思想是,我们可以一步步地构建这个多项式,每次只增加一个数据点。想象一下,你正在画一条曲线,每次只根据一个新的点来调整曲线的形状。
首先,我们定义 p k p_k p k k + 1 k+1 k + 1 ( x 0 , y 0 ) , … , ( x k , y k ) (x_0, y_0), \ldots, (x_k, y_k) ( x 0 , y 0 ) , … , ( x k , y k )
当 k = 0 k=0 k = 0 p 0 p_0 p 0 y y y
p 0 ( x ) = y 0 . p_0(x) = y_0.
p 0 ( x ) = y 0 .
假设我们已经知道 p k − 1 p_{k-1} p k − 1 k k k k + 1 k+1 k + 1 ( x k , y k ) (x_k, y_k) ( x k , y k ) p k − 1 p_{k-1} p k − 1 p k p_k p k
p k = p k − 1 + c k ( x − x 0 ) ⋯ ( x − x k − 1 ) . p_k = p_{k-1} + c_k(x-x_0)\cdots(x-x_{k-1}).
p k = p k − 1 + c k ( x − x 0 ) ⋯ ( x − x k − 1 ) .
这里的 c k c_k c k i < k i < k i < k ( x − x 0 ) ⋯ ( x − x k − 1 ) (x-x_0)\cdots(x-x_{k-1}) ( x − x 0 ) ⋯ ( x − x k − 1 ) x i x_i x i c k c_k c k p k ( x k ) = y k p_k(x_k) = y_k p k ( x k ) = y k
通过这种方法,我们就可以逐步构建出牛顿插值多项式:
p k = c 0 + c 1 ( x − x 0 ) + c 2 ( x − x 0 ) ( x − x 1 ) + ⋯ + c k ( x − x 0 ) ⋯ ( x − x k − 1 ) p_k = c_0 + c_1(x-x_0) + c_2(x-x_0)(x-x_1) + \cdots + c_k(x-x_0)\cdots(x-x_{k-1})
p k = c 0 + c 1 ( x − x 0 ) + c 2 ( x − x 0 ) ( x − x 1 ) + ⋯ + c k ( x − x 0 ) ⋯ ( x − x k − 1 )
或者用一个更简洁的表示方式:
p k = ∑ j = 0 k c j ∏ i = 0 j − 1 ( x − x i ) p_k = \sum_{j=0}^k c_j \prod_{i=0}^{j-1}(x-x_i)
p k = j = 0 ∑ k c j i = 0 ∏ j − 1 ( x − x i )
这里的 ∏ i = 0 − 1 ⋯ \prod_{i=0}^{-1}\cdots ∏ i = 0 − 1 ⋯
值得注意的是,每个系数 c j c_j c j j + 1 j+1 j + 1 c j c_j c j
我们有时需要用一种特别的方法来理解和处理数据点之间的关系,这种方法叫做差分。想象一下,你有一串珠子,差分就像是观察并记录每两颗珠子之间的距离。
首先,对于单个数据点 ( x i , y i ) (x_i, y_i) ( x i , y i ) f [ x i ] f[x_i] f [ x i ] y i y_i y i
接着,如果我们有两个相邻的数据点 ( x i − 1 , y i − 1 ) (x_{i-1}, y_{i-1}) ( x i − 1 , y i − 1 ) ( x i , y i ) (x_i, y_i) ( x i , y i )
f [ x i − 1 , x i ] = f [ x i ] − f [ x i − 1 ] x i − x i − 1 f[x_{i-1}, x_i] = \frac{f[x_i] - f[x_{i-1}]}{x_i - x_{i-1}}
f [ x i − 1 , x i ] = x i − x i − 1 f [ x i ] − f [ x i − 1 ]
这其实就是在计算这两个点之间的变化率。
当我们有更多的点时,我们可以用同样的方法,逐步扩展差分的计算。对于一系列的点 x i , x i + 1 , … , x j x_i, x_{i+1}, \ldots, x_j x i , x i + 1 , … , x j
f [ x i , x i + 1 , … , x j − 1 , x j ] = f [ x i + 1 , … , x j − 1 , x j ] − f [ x i , x i + 1 , … , x j − 1 ] x j − x i f[x_i, x_{i+1}, \ldots, x_{j-1}, x_j] = \frac{f[x_{i+1}, \ldots, x_{j-1}, x_j] - f[x_i, x_{i+1}, \ldots, x_{j-1}]}{x_j - x_i}
f [ x i , x i + 1 , … , x j − 1 , x j ] = x j − x i f [ x i + 1 , … , x j − 1 , x j ] − f [ x i , x i + 1 , … , x j − 1 ]
为了让这些计算看起来不那么复杂,我们用 γ j ℓ \gamma_{j\ell} γ j ℓ ℓ \ell ℓ γ j ℓ \gamma_{j\ell} γ j ℓ
γ j 0 = y j , γ j ℓ = γ j , ℓ − 1 − γ j − 1 , ℓ − 1 x j − x j − ℓ \gamma_{j0} = y_j, \quad \gamma_{j\ell} = \frac{\gamma_{j, \ell-1} - \gamma_{j-1, \ell-1}}{x_j - x_{j-\ell}}
γ j 0 = y j , γ j ℓ = x j − x j − ℓ γ j , ℓ − 1 − γ j − 1 , ℓ − 1
这个方法可以帮助我们构建牛顿插值多项式。这种多项式可以精确地通过我们给定的点 ( x 0 , y 0 ) , … , ( x n , y n ) (x_0, y_0), \ldots, (x_n, y_n) ( x 0 , y 0 ) , … , ( x n , y n )
p n ( x ) = f [ x 0 ] + ∑ j = 1 n f [ x 0 , x 1 , … , x j ] ∏ i = 0 j − 1 ( x − x i ) p_n(x) = f[x_0] + \sum_{j=1}^n f[x_0, x_1, \ldots, x_j] \prod_{i=0}^{j-1}(x - x_i)
p n ( x ) = f [ x 0 ] + j = 1 ∑ n f [ x 0 , x 1 , … , x j ] i = 0 ∏ j − 1 ( x − x i )
虽然这个公式看起来有点复杂,但它实际上提供了一个非常高效的方式来计算和评估插值多项式。
让我们用一个具体的例子来展示这个方法。假设我们有一个函数 f ( x ) = x 3 − 2 x 2 + 1 f(x) = x^3 - 2x^2 + 1 f ( x ) = x 3 − 2 x 2 + 1 x i = 0 , 1 , 2 , 3 x_i = 0, 1, 2, 3 x i = 0 , 1 , 2 , 3
i x i γ j 0 γ j 1 γ j 2 γ j 3 0 0 f [ x 0 ] 1 1 f [ x 1 ] f [ x 0 , x 1 ] 2 2 f [ x 2 ] f [ x 1 , x 2 ] f [ x 0 , x 1 , x 2 ] 3 3 f [ x 3 ] f [ x 2 , x 3 ] f [ x 1 , x 2 , x 3 ] f [ x 0 , x 1 , x 2 , x 3 ] \begin{array}{c|c|c|c|c}
i & x_i & \gamma_{j0} & \gamma_{j1} & \gamma_{j2} & \gamma_{j3} \\
\hline
0 & 0 & \color{red}{f[x_0]} & & & \\
1 & 1 & f[x_1] & \color{red}{f[x_0,x_1]} & & \\
2 & 2 & f[x_2] & f[x_1,x_2] & \color{red}{f[x_0,x_1,x_2]} & \\
3 & 3 & f[x_3] & f[x_2,x_3] & f[x_1,x_2,x_3] & \color{red}{f[x_0,x_1,x_2,x_3]} \\
\end{array}
i 0 1 2 3 x i 0 1 2 3 γ j 0 f [ x 0 ] f [ x 1 ] f [ x 2 ] f [ x 3 ] γ j 1 f [ x 0 , x 1 ] f [ x 1 , x 2 ] f [ x 2 , x 3 ] γ j 2 f [ x 0 , x 1 , x 2 ] f [ x 1 , x 2 , x 3 ] γ j 3 f [ x 0 , x 1 , x 2 , x 3 ]
通过这种方式,我们可以非常直观地看到每个差分是如何计算的。例如,在这个特定的例子中,我们可以计算出:
γ 11 = f [ x 0 , x 1 ] = − 1 , γ 22 = f [ x 0 , x 1 , x 2 ] = 1 , γ 33 = f [ x 0 , x 1 , x 2 , x 3 ] = 1 \gamma_{11} = f[x_0, x_1] = -1, \quad \gamma_{22} = f[x_0, x_1, x_2] = 1, \quad \gamma_{33} = f[x_0, x_1, x_2, x_3] = 1
γ 1 1 = f [ x 0 , x 1 ] = − 1 , γ 2 2 = f [ x 0 , x 1 , x 2 ] = 1 , γ 3 3 = f [ x 0 , x 1 , x 2 , x 3 ] = 1
最后,我们可以根据这些差分构建我们的牛顿插值多项式 p 3 ( x ) p_3(x) p 3 ( x )
p 3 ( x ) = 1 − x + x ( x − 1 ) + x ( x − 1 ) ( x − 2 ) p_3(x) = 1 - x + x(x - 1) + x(x - 1)(x - 2)
p 3 ( x ) = 1 − x + x ( x − 1 ) + x ( x − 1 ) ( x − 2 )
这个构建的多项式 p 3 ( x ) p_3(x) p 3 ( x ) f ( x ) f(x) f ( x )
在实际应用中,我们通常会先构造一个插值多项式,然后用它来估算大量点的值。这个过程中,如何高效地计算多项式在这些点上的值变得尤为重要。
牛顿形式的插值多项式提供了一种高效的评估方法,这种方法称为霍纳方法。这个方法的思想是从多项式的最高次项开始,逐步向下计算。牛顿形式的多项式可以这样表示:
p n ( x ) = c 0 + ( x − x 0 ) ( c 1 + ( x − x 1 ) ( c 2 + ⋯ + ( x − x n − 1 ) c n ) ⋯ ) p_n(x) = c_0 + (x - x_0) \left( c_1 + (x - x_1) \left( c_2 + \cdots + (x - x_{n-1})c_n \right) \cdots \right)
p n ( x ) = c 0 + ( x − x 0 ) ( c 1 + ( x − x 1 ) ( c 2 + ⋯ + ( x − x n − 1 ) c n ) ⋯ )
这里的 c j = f [ x 0 , x 1 , ⋯ , x j ] c_j = f[x_0, x_1, \cdots, x_j] c j = f [ x 0 , x 1 , ⋯ , x j ]
基于这个形式,我们可以设计一个简单而有效的算法来计算 p n ( x ) p_n(x) p n ( x ) x x x ( x 0 , y 0 ) , … , ( x n , y n ) (x_0, y_0), \ldots, (x_n, y_n) ( x 0 , y 0 ) , … , ( x n , y n ) ( c 0 , … , c n ) (c_0, \ldots, c_n) ( c 0 , … , c n )
初始化 y y y c n c_n c n
从 n − 1 n-1 n − 1
y ← c k + ( x − x k ) ⋅ y y \gets c_k + (x - x_k) \cdot y
y ← c k + ( x − x k ) ⋅ y
返回最终计算出的 y y y
这个算法大约需要 3 n 3n 3 n
C++示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <iostream> #include <vector> double evaluateNewtonPolynomial (const std::vector<double >& x, const std::vector<double >& c, double evalPoint) int n = c.size () - 1 ; double y = c[n]; for (int k = n - 1 ; k >= 0 ; k--) { y = c[k] + (evalPoint - x[k]) * y; } return y; } int main () std::vector<double > x = {1 , 2 , 3 }; std::vector<double > c = {2 , -1 , 3 }; double evalPoint = 1.5 ; double result = evaluateNewtonPolynomial (x, c, evalPoint); std::cout << "The value of the polynomial at x = " << evalPoint << " is: " << result << std::endl; return 0 ; }
在数学中,差分的概念可以被广泛地推广和应用。核心思想是,只要每个点 x i x_i x i
通常情况下,我们考虑的这些点 x i x_i x i
差分的概念也可以被扩展到包含重复的点。这种情况通常出现在我们想要插值某个函数的导数时。例如,在赫尔米特插值(Hermite interpolation)中,就需要考虑这种情况。
当点 x i x_i x i
差分是一个非常强大的工具,它能够以多种方式适应和解决不同的数学问题。
当我们使用多项式插值来估算一个函数 f f f p n p_n p n f ( x ) f(x) f ( x )
假设我们有一个插值多项式 p n p_n p n ( x 0 , x 1 , … , x n ) (x_0, x_1, \ldots, x_n) ( x 0 , x 1 , … , x n ) f f f
p n ( x j ) = f ( x j ) , j = 0 , … , n . p_n(x_j) = f(x_j), \quad j=0,\ldots,n.
p n ( x j ) = f ( x j ) , j = 0 , … , n .
这些点都位于某个区间 [ a , b ] [a, b] [ a , b ]
如果我们希望 p n p_n p n f f f [ c , d ] [c, d] [ c , d ] [ a , b ] [a, b] [ a , b ] p n ( x ) p_n(x) p n ( x ) f ( x ) f(x) f ( x )
max x ∈ [ c , d ] ∣ f ( x ) − p n ( x ) ∣ . \max_{x \in [c, d]} |f(x) - p_n(x)|.
x ∈ [ c , d ] max ∣ f ( x ) − p n ( x ) ∣ .
那么,我们面临的关键问题包括:
插值误差的界限是什么?
这个误差界限如何受到 n n n
误差界限在不同区间上如何变化?
找到这些问题的答案,可以帮助我们制定策略,在某个特定区间内通过插值来近似函数 f f f x 0 x_0 x 0 x n x_n x n
当 x x x p n ( x ) p_n(x) p n ( x ) f ( x ) f(x) f ( x )
在探讨插值多项式的误差公式之前,把它和泰勒定理进行对比是非常有帮助的。在泰勒定理的情况下,我们有一个函数 f f f x 0 x_0 x 0 x 0 x_0 x 0 n n n
f ( x 0 ) , f ′ ( x 0 ) , … , f ( n ) ( x 0 ) f(x_0), f'(x_0), \ldots, f^{(n)}(x_0)
f ( x 0 ) , f ′ ( x 0 ) , … , f ( n ) ( x 0 )
基于这些信息,我们可以构造一个多项式 T n ( x ) T_n(x) T n ( x ) f f f
f ( x ) = T n ( x ) + R n ( x ) f(x) = T_n(x) + R_n(x)
f ( x ) = T n ( x ) + R n ( x )
其中,T n ( x ) T_n(x) T n ( x )
T n ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + f ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + ⋯ + f ( n ) ( x 0 ) n ! ( x − x 0 ) n T_n(x) = f(x_0) + f'(x_0)(x-x_0) + \frac{f''(x_0)}{2!}(x-x_0)^2 + \cdots + \frac{f^{(n)}(x_0)}{n!}(x-x_0)^n
T n ( x ) = f ( x 0 ) + f ′ ( x 0 ) ( x − x 0 ) + 2 ! f ′ ′ ( x 0 ) ( x − x 0 ) 2 + ⋯ + n ! f ( n ) ( x 0 ) ( x − x 0 ) n
而 R n ( x ) R_n(x) R n ( x )
R n ( x ) = f ( n + 1 ) ( ξ x ) ( n + 1 ) ! ( x − x 0 ) n + 1 R_n(x) = \frac{f^{(n+1)}(\xi_x)}{(n+1)!}(x-x_0)^{n+1}
R n ( x ) = ( n + 1 ) ! f ( n + 1 ) ( ξ x ) ( x − x 0 ) n + 1
这里 ξ x \xi_x ξ x x 0 x_0 x 0 x x x
对于插值多项式,我们有 n + 1 n+1 n + 1
f ( x 0 ) , … , f ( x n ) f(x_0), \ldots, f(x_n)
f ( x 0 ) , … , f ( x n )
在 n + 1 n+1 n + 1
定理(拉格朗日误差公式) :假设 f ∈ C n + 1 ( [ a , b ] ) f \in C^{n+1}([a,b]) f ∈ C n + 1 ( [ a , b ] ) n + 1 n+1 n + 1
x 0 < x 1 < ⋯ < x n x_0 < x_1 < \cdots < x_n
x 0 < x 1 < ⋯ < x n
都包含在区间 [ a , b ] [a, b] [ a , b ] p n ( x ) p_n(x) p n ( x ) x ∈ [ a , b ] x \in [a, b] x ∈ [ a , b ]
f ( x ) = p n ( x ) + E ( x ) f(x) = p_n(x) + E(x)
f ( x ) = p n ( x ) + E ( x )
其中误差项 E ( x ) E(x) E ( x )
E ( x ) = f ( n + 1 ) ( ξ x ) ( n + 1 ) ! ∏ j = 0 n ( x − x j ) E(x) = \frac{f^{(n+1)}(\xi_x)}{(n+1)!} \prod_{j=0}^n (x - x_j)
E ( x ) = ( n + 1 ) ! f ( n + 1 ) ( ξ x ) j = 0 ∏ n ( x − x j )
这里的 ξ x \xi_x ξ x x x x [ a , b ] [a, b] [ a , b ]
注意这个误差公式在形式上和泰勒定理非常相似,除了多项式的形式是 ( x − x 0 ) ⋯ ( x − x n ) (x-x_0)\cdots(x-x_n) ( x − x 0 ) ⋯ ( x − x n ) ( x − x 0 ) n + 1 (x-x_0)^{n+1} ( x − x 0 ) n + 1
值得指出的是,这个定理不仅适用于插值(x x x [ x 0 , x n ] [x_0, x_n] [ x 0 , x n ] x x x [ x 0 , x n ] [x_0, x_n] [ x 0 , x n ]
在讨论多项式插值的误差时,我们发现误差的大小通常由三个主要因素决定:
( n + 1 ) (n+1) ( n + 1 ) f f f M M M [ a , b ] [a, b] [ a , b ] ( n + 1 ) (n+1) ( n + 1 )
M = max x ∈ [ a , b ] ∣ f ( n + 1 ) ( x ) ∣ . M = \max_{x \in [a, b]} |f^{(n+1)}(x)|.
M = x ∈ [ a , b ] max ∣ f ( n + 1 ) ( x ) ∣ .
由于 ξ x \xi_x ξ x [ a , b ] [a, b] [ a , b ] M M M
节点间距离的影响 :这个因素取决于插值节点 x j x_j x j x x x x x x x x x
因子 ( 1 / ( n + 1 ) ! ) (1/(n+1)!) ( 1 / ( n + 1 ) ! ) :这个因子随着 n n n n n n n n n
基于这些因素,我们可以得到误差的一个上界,即在某个区间 I I I p n ( x ) p_n(x) p n ( x ) f ( x ) f(x) f ( x )
max x ∈ I ∣ p n ( x ) − f ( x ) ∣ = max x ∈ I ∣ E n ( x ) ∣ ≤ M ( n + 1 ) ! max x ∈ I ∣ ω n + 1 ( x ) ∣ . \max_{x \in I} |p_n(x) - f(x)| = \max_{x \in I} |E_n(x)| \le \frac{M}{(n+1)!} \max_{x \in I} |\omega_{n+1}(x)|.
x ∈ I max ∣ p n ( x ) − f ( x ) ∣ = x ∈ I max ∣ E n ( x ) ∣ ≤ ( n + 1 ) ! M x ∈ I max ∣ ω n + 1 ( x ) ∣ .
需要注意的是,即使我们知道 x x x I I I ( n + 1 ) (n+1) ( n + 1 ) ξ \xi ξ I I I f ( n + 1 ) f^{(n+1)} f ( n + 1 ) [ a , b ] [a, b] [ a , b ]
另一方面,ω \omega ω I I I [ x 1 , x 2 ] [x_1, x_2] [ x 1 , x 2 ] ω \omega ω [ x 1 , x 2 ] [x_1, x_2] [ x 1 , x 2 ] f ( n + 1 ) f^{(n+1)} f ( n + 1 ) [ a , b ] [a, b] [ a , b ]
以一个具体的例子来理解多项式插值的误差。f ( x ) = e x f(x) = e^x f ( x ) = e x x 1 = 0 x_1 = 0 x 1 = 0 x 2 = 1 x_2 = 1 x 2 = 1
p 1 = 1 + ( e − 1 ) x p_1 = 1 + (e - 1)x
p 1 = 1 + ( e − 1 ) x
对于这个插值多项式,误差的形式为:
E ( x ) = f ′ ′ ( ξ x ) 2 ! x ( x − 1 ) E(x) = \frac{f''(\xi_x)}{2!}x(x - 1)
E ( x ) = 2 ! f ′ ′ ( ξ x ) x ( x − 1 )
这里的 ξ x \xi_x ξ x f ′ ′ ( x ) f''(x) f ′ ′ ( x ) f ′ ′ ( x ) = e x f''(x) = e^x f ′ ′ ( x ) = e x
M = max x ∈ [ 0 , 1 ] ∣ e x ∣ ≤ e M = \max_{x \in [0,1]}|e^x| \le e
M = x ∈ [ 0 , 1 ] max ∣ e x ∣ ≤ e
对于其他项,我们可以找到 x ( x − 1 ) x(x - 1) x ( x − 1 ) x = 1 / 2 x = 1/2 x = 1 / 2
max x ∈ [ 0 , 1 ] ∣ x ( x − 1 ) ∣ ≤ 1 4 \max_{x \in [0,1]}|x(x - 1)| \le \frac{1}{4}
x ∈ [ 0 , 1 ] max ∣ x ( x − 1 ) ∣ ≤ 4 1
因此,我们得到误差的一个上界:
∣ p 1 ( x ) − f ( x ) ∣ ≤ e 8 ≈ 0.34 ,对于 x 在 [ 0 , 1 ] 内 |p_1(x) - f(x)| \le \frac{e}{8} \approx 0.34,对于 x 在 [0,1] 内
∣ p 1 ( x ) − f ( x ) ∣ ≤ 8 e ≈ 0 . 3 4 , 对 于 x 在 [ 0 , 1 ] 内
虽然这个近似不是非常理想,但考虑到 p 1 p_1 p 1 p 1 p_1 p 1 f ( x ) = e x f(x) = e^x f ( x ) = e x
∣ p 1 ( x ) − f ( x ) ∣ ≤ 2 e 2 ≈ 15 ,对于 x 在 [ 0 , 1 ] 内。 |p_1(x) - f(x)| \le 2e^2 \approx 15,对于 x 在 [0,1] 内。
∣ p 1 ( x ) − f ( x ) ∣ ≤ 2 e 2 ≈ 1 5 , 对 于 x 在 [ 0 , 1 ] 内 。
现在,回到区间 [0,1],假设我们使用 10 个等间距的点 x j = j h x_j = jh x j = j h j = 0 , … , 9 j=0, \ldots, 9 j = 0 , … , 9 h = 1 / 9 h = 1/9 h = 1 / 9
E ( x ) = f ( 10 ) ( ξ x ) 10 ! ∏ j = 0 9 ( x − x j ) E(x) = \frac{f^{(10)}(\xi_x)}{10!} \prod_{j=0}^{9}(x - x_j)
E ( x ) = 1 0 ! f ( 1 0 ) ( ξ x ) j = 0 ∏ 9 ( x − x j )
对于 f ( 10 ) ( ξ x ) f^{(10)}(\xi_x) f ( 1 0 ) ( ξ x )
∣ f ( 10 ) ( ξ x ) ∣ ≤ e |f^{(10)}(\xi_x)| \le e
∣ f ( 1 0 ) ( ξ x ) ∣ ≤ e
对于乘积项,我们可以做一个粗略的估计,注意到对于所有的 j j j ∣ x − x j ∣ ≤ 1 |x - x_j| \le 1 ∣ x − x j ∣ ≤ 1
∣ E ( x ) ∣ ≤ e 10 ! ≈ 7.5 × 1 0 − 7 |E(x)| \le \frac{e}{10!} \approx 7.5 \times 10^{-7}
∣ E ( x ) ∣ ≤ 1 0 ! e ≈ 7 . 5 × 1 0 − 7
实际上,这个估计可能过于保守,因为一些节点 x j x_j x j x x x
假设我们有以下一系列等间距的点,间距为 h h h
a = x 0 < x 1 < ⋯ < x n = b a = x_0 < x_1 < \cdots < x_n = b
a = x 0 < x 1 < ⋯ < x n = b
x i = a + j h , h = b − a n . x_{i}=a+jh,\quad h=\frac{b-a}{n}.
x i = a + j h , h = n b − a .
现在,我们关注一个位于区间 [ a , b ] [a, b] [ a , b ] x x x x x x
具体来说,假设 x x x [ x 0 , x 1 ] [x_0, x_1] [ x 0 , x 1 ]
∣ x − x j ∣ ≤ ( j + 1 ) h 对于 j = 0 , ⋯ , n |x - x_j| \le (j + 1)h \text{ 对于 } j = 0, \cdots, n
∣ x − x j ∣ ≤ ( j + 1 ) h 对于 j = 0 , ⋯ , n
这意味着 x x x x j x_j x j ( j + 1 ) h (j+1)h ( j + 1 ) h
因此,当我们确信 x x x [ x 1 , b ] [x_1, b] [ x 1 , b ]
∣ ω n + 1 ( x ) ∣ ≤ ∏ j = 0 n ∣ x − x j ∣ ≤ ( n + 1 ) ! h n + 1 对于 x ∈ [ a , b ] |\omega_{n+1}(x)| \le \prod_{j=0}^n |x - x_j| \le (n+1)!h^{n+1} \text{ 对于 } x \in [a, b]
∣ ω n + 1 ( x ) ∣ ≤ j = 0 ∏ n ∣ x − x j ∣ ≤ ( n + 1 ) ! h n + 1 对于 x ∈ [ a , b ]
基于这个结果,我们可以得出 n n n E n E_n E n h n + 1 h^{n+1} h n + 1 h → 0 h \to 0 h → 0 f f f ( n + 1 ) (n+1) ( n + 1 ) ( n + 1 ) (n+1) ( n + 1 )
例如,考虑函数 f ( x ) = 1 / x f(x) = 1/x f ( x ) = 1 / x [ 1 , 2 ] [1, 2] [ 1 , 2 ] x ∈ [ 1 , 2 ] x \in [1, 2] x ∈ [ 1 , 2 ]
∣ f ( n + 1 ) ( x ) ∣ ≤ ( n + 1 ) ! ( max x ∈ [ 1 , 2 ] ∣ 1 / x ∣ ) = ( n + 1 ) ! |f^{(n+1)}(x)| \le (n+1)! \left(\max_{x \in [1, 2]} |1/x|\right) = (n+1)!
∣ f ( n + 1 ) ( x ) ∣ ≤ ( n + 1 ) ! ( x ∈ [ 1 , 2 ] max ∣ 1 / x ∣ ) = ( n + 1 ) !
在这种情况下,h n + 1 h^{n+1} h n + 1 ( n + 1 ) ! (n+1)! ( n + 1 ) !
∣ E n ( x ) ∣ ≤ ( n + 1 ) ! ( 1 n ) n + 1 ∼ 2 π n e e − n 当 n → ∞ |E_n(x)| \le (n+1)! \left(\frac{1}{n}\right)^{n+1} \sim \frac{\sqrt{2\pi n}}{e}e^{-n} \text{ 当 } n \to \infty
∣ E n ( x ) ∣ ≤ ( n + 1 ) ! ( n 1 ) n + 1 ∼ e 2 π n e − n 当 n → ∞
这里我们使用了斯特林近似:
n ! ∼ e − n n n 2 π n 当 n → ∞ n! \sim e^{-n}n^n\sqrt{2\pi n} \text{ 当 } n \to \infty
n ! ∼ e − n n n 2 π n 当 n → ∞
这种抵消效果是典型的,并且通常会导致误差的指数级衰减。然而,也存在一些极端情况,其中 ( n + 1 ) (n+1) ( n + 1 )
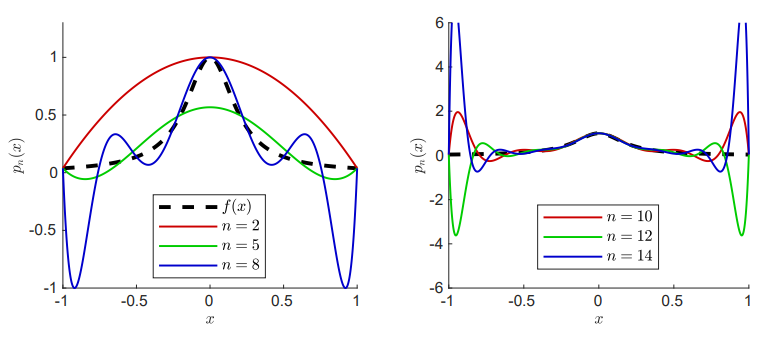
当我们尝试通过增加插值节点来改善插值多项式的精度时,情况并不总是像我们预期的那样。一个经典的例子是,对于看似稳定的函数:
1 x 2 + 25 \frac{1}{x^2+25}
x 2 + 2 5 1
我们在区间 [-1,1] 内使用等间距的节点:
− 1 = x 0 < ⋯ < x n = 1 -1 = x_0 < \cdots < x_n = 1
− 1 = x 0 < ⋯ < x n = 1
来构建插值多项式 p n ( x ) p_n(x) p n ( x ) n n n n n n
实际上,插值多项式和函数之间的最大误差:
max x ∈ [ − 1 , 1 ] ∣ p n ( x ) − f ( x ) ∣ \max_{x \in [-1,1]} |p_n(x) - f(x)|
x ∈ [ − 1 , 1 ] max ∣ p n ( x ) − f ( x ) ∣
误差随着 n → ∞ n \to \infty n → ∞
那么这种现象和误差公式有什么关联呢?关键在于这两个竞争因素:
f ( n + 1 ) ( ξ ) ( n + 1 ) ! 和 ω n + 1 ( x ) = ∏ j = 0 n ( x − x j ) \frac{f^{(n+1)}(\xi)}{(n+1)!} \quad \text{和} \quad \omega_{n+1}(x) = \prod_{j=0}^n (x - x_j)
( n + 1 ) ! f ( n + 1 ) ( ξ ) 和 ω n + 1 ( x ) = j = 0 ∏ n ( x − x j )
可以验证,对于较大的 n n n f ( n ) / ( n + 1 ) ! f^{(n)} / (n+1)! f ( n ) / ( n + 1 ) ! n n n ω n + 1 / ( n + 1 ) ! \omega_{n+1} / (n+1)! ω n + 1 / ( n + 1 ) ! ω n \omega_n ω n ω n \omega_n ω n n n n
x j = cos ( 2 j + 1 2 n π ) , j = 0 , … , n − 1 x_j = \cos\left(\frac{2j+1}{2n}\pi\right), \quad j = 0, \ldots, n-1
x j = cos ( 2 n 2 j + 1 π ) , j = 0 , … , n − 1
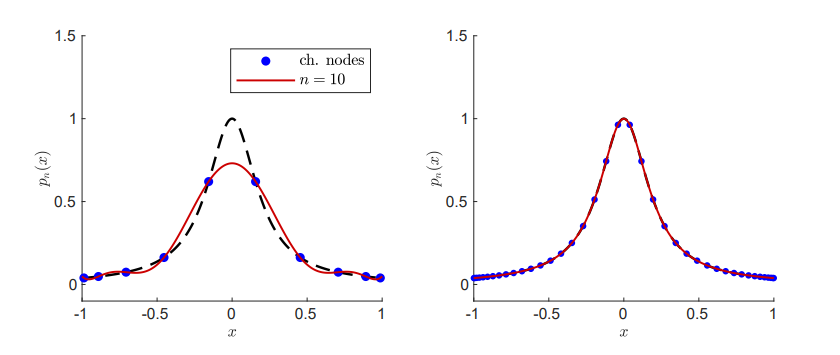
如图所示,对于 n = 10 n=10 n = 1 0 n = 50 n=50 n = 5 0
所以,问题并不在于点数本身的增加,而在于点的分布。合理选择插值点可以显著改善插值多项式的性能。
关键点 :这里的教训是,等间距的高阶插值多项式可能会导致灾难性的结果,如果可能,应该避免使用。然而,通过合理选择插值点,即使是高阶的插值多项式也可以发挥良好的效果。
更多背景:一般来说,哪些点集和函数会导致问题,这是一个复杂的问题。事实上,对于任何给定的选择点的方案,都有可能找到一个特定的函数来引发问题,即使是对于切比雪夫节点。然而,对于这些节点导致问题的函数,在实际应用中通常是极端的异常情况,这使得切比雪夫节点成为多数“合理”函数的良好选择。
在龙格现象的例子中,问题在于函数 f f f f f f
对于高阶插值可能带来的问题,分段插值提供了一个完全不同的解决方案。与其在整个区间上使用一个高阶多项式,不如在每个小的子区间上使用低阶(通常是最高三阶)的多项式。这样的做法避免了之前提到的高阶插值中的问题。具体来说,我们有以下节点:
x 0 < x 1 < ⋯ < x n x_0 < x_1 < \cdots < x_n
x 0 < x 1 < ⋯ < x n
对于每个子区间 [ x i , x i + 1 ] [x_i, x_{i+1}] [ x i , x i + 1 ] h = x i + 1 − x i h = x_{i+1} - x_i h = x i + 1 − x i
分段线性插值的一个缺点是,它在节点处不可微。换句话说,曲线在这些点上可能有尖锐的转折,这在某些应用中可能不是理想的特性。
对于需要函数值和导数都很平滑的场景,三次样条是一个常见的选择。这种方法的思想是,在每个子区间上使用三次插值多项式,并且利用以下数据:
f ( x i ) , f ′ ( x i ) , f ( x i + 1 ) , f ′ ( x i + 1 ) f(x_i), f'(x_i), f(x_{i+1}), f'(x_{i+1})
f ( x i ) , f ′ ( x i ) , f ( x i + 1 ) , f ′ ( x i + 1 )
这实际上是一种称为赫尔米特插值的方法,它不仅匹配函数值,还匹配导数。然后,我们将这些插值多项式“粘合”在一起,确保在节点处函数值和导数都连续,从而创建一个整体上连续且平滑的插值多项式。
在需要根据数据构建复杂函数表示的场景中,比如在计算机图形学中用于形状轮廓的绘制,三次样条是一种常见的选择,它能够提供既平滑又准确的插值结果。
在理解插值多项式时,了解其形式及其构建方法至关重要。我们已知,对于 n + 1 n+1 n + 1 ( x 0 , … , x n ) (x_0, \ldots, x_n) ( x 0 , … , x n ) p n ( x ) p_n(x) p n ( x ) f ( x ) f(x) f ( x )
p n ( x j ) = f ( x j ) , j = 0 , … , n p_n(x_j) = f(x_j), \quad j=0, \ldots, n
p n ( x j ) = f ( x j ) , j = 0 , … , n
此多项式可以用牛顿形式表示,而牛顿形式中的系数可以通过递归方法定义和计算:
f [ x i ] = f ( x i ) f[x_i] = f(x_i)
f [ x i ] = f ( x i )
f [ x i , x i + 1 , … , x j − 1 , x j ] = f [ x i + 1 , … , x j − 1 , x j ] − f [ x i , x i + 1 , … , x j − 1 ] x j − x i f[x_i, x_{i+1}, \ldots, x_{j-1}, x_j] = \frac{f[x_{i+1}, \ldots, x_{j-1}, x_j] - f[x_i, x_{i+1}, \ldots, x_{j-1}]}{x_j - x_i}
f [ x i , x i + 1 , … , x j − 1 , x j ] = x j − x i f [ x i + 1 , … , x j − 1 , x j ] − f [ x i , x i + 1 , … , x j − 1 ]
在证明牛顿形式的有效性时,我们不是通过递归定义这些系数,而是直接将它们定义为多项式 ( ∏ i = 0 j − 1 ( x − x i ) ) (\prod_{i=0}^{j-1}(x-x_i)) ( ∏ i = 0 j − 1 ( x − x i ) )
具体地,我们从常数多项式开始,即插值点 ( x i , f ( x i ) ) (x_i, f(x_i)) ( x i , f ( x i ) ) p n − 1 ( x ) p_{n-1}(x) p n − 1 ( x ) p n ( x ) p_n(x) p n ( x ) p n ( x ) p_n(x) p n ( x ) p n − 1 ( x ) p_{n-1}(x) p n − 1 ( x )
p n ( x ) = p n − 1 ( x ) + x − x 0 x n − x 0 ( q ( x ) − p n − 1 ( x ) ) p_n(x) = p_{n-1}(x) + \frac{x - x_0}{x_n - x_0} (q(x) - p_{n-1}(x))
p n ( x ) = p n − 1 ( x ) + x n − x 0 x − x 0 ( q ( x ) − p n − 1 ( x ) )
这里的动机是让 p n − 1 ( x ) p_{n-1}(x) p n − 1 ( x ) p n ( x ) p_n(x) p n ( x ) x 0 , … , x n − 1 x_0, \ldots, x_{n-1} x 0 , … , x n − 1 x n x_n x n g ( x ) ( q ( x ) − p n − 1 ( x ) ) g(x)(q(x)-p_{n-1}(x)) g ( x ) ( q ( x ) − p n − 1 ( x ) ) g ( x ) g(x) g ( x ) x n x_n x n x 0 x_0 x 0 g ( x ) = x − x 0 x n − x 0 g(x) = \frac{x - x_0}{x_n - x_0} g ( x ) = x n − x 0 x − x 0
通过这种方法,我们可以确保在所有插值点上 p n ( x ) p_n(x) p n ( x ) f ( x ) f(x) f ( x ) n n n n + 1 n+1 n + 1
接下来,我们分析误差。当我们将 x x x x 0 , … , x n , x x_0, \ldots, x_n, x x 0 , … , x n , x f f f n + 1 n+1 n + 1 f f f n + 1 n+1 n + 1
g ( t ) : = p n ( t ) + f [ x 0 , … , x n , x ] ∏ j = 0 n ( t − x j ) g(t) := p_n(t) + f[x_0, \ldots, x_n, x] \prod_{j=0}^n (t - x_j)
g ( t ) : = p n ( t ) + f [ x 0 , … , x n , x ] j = 0 ∏ n ( t − x j )
然后,我们考虑 h ( t ) : = f ( t ) − g ( t ) h(t) := f(t) - g(t) h ( t ) : = f ( t ) − g ( t ) g ( t ) g(t) g ( t ) x 0 , … , x n , x x_0, \ldots, x_n, x x 0 , … , x n , x f f f h ( t ) h(t) h ( t ) n + 2 n+2 n + 2 [ a , b ] [a, b] [ a , b ] k k k ( a , b ) (a, b) ( a , b ) k − 1 k-1 k − 1 h ( n + 1 ) h^{(n+1)} h ( n + 1 ) [ a , b ] [a, b] [ a , b ] ξ x \xi_x ξ x
f [ x 0 , … , x n , x ] = f ( n + 1 ) ( ξ x ) ( n + 1 ) ! f[x_0, \ldots, x_n, x] = \frac{f^{(n+1)}(\xi_x)}{(n+1)!}
f [ x 0 , … , x n , x ] = ( n + 1 ) ! f ( n + 1 ) ( ξ x )
最终,由于 g ( x ) g(x) g ( x ) x x x f f f
f ( x ) = p n ( x ) + f ( n + 1 ) ( ξ x ) ( n + 1 ) ! ∏ j = 0 n ( x − x j ) f(x) = p_n(x) + \frac{f^{(n+1)}(\xi_x)}{(n+1)!} \prod_{j=0}^n (x - x_j)
f ( x ) = p n ( x ) + ( n + 1 ) ! f ( n + 1 ) ( ξ x ) j = 0 ∏ n ( x − x j )
这就是误差公式,揭示了插值多项式和实际函数之间的差距。
赫米特插值是一种特殊的插值方法,它不仅匹配了节点处的函数值,而且还匹配了节点处函数值的导数。这种方法的目标是构建一个多项式 p p p x j x_j x j j = 0 , 1 , 2 , … , n j = 0, 1, 2, \ldots, n j = 0 , 1 , 2 , … , n
p ( x j ) = f ( x j ) , p ′ ( x j ) = f ′ ( x j ) p(x_j) = f(x_j), \quad p'(x_j) = f'(x_j)
p ( x j ) = f ( x j ) , p ′ ( x j ) = f ′ ( x j )
赫米特插值可以扩展到每个点有任意数量的导数情况。关键定理表明,给定一个函数 f f f x j x_j x j p p p 2 n + 1 2n+1 2 n + 1
值得注意的是,这个多项式的度数是 2 n + 1 2n+1 2 n + 1 2 n + 2 2n+2 2 n + 2
f ( x ) = p ( x ) + f ( 2 n + 2 ) ( x ) ( 2 n + 2 ) ! ∏ j = 0 n ( x − x j ) 2 f(x) = p(x) + \frac{f^{(2n+2)}(x)}{(2n+2)!} \prod_{j=0}^n (x - x_j)^2
f ( x ) = p ( x ) + ( 2 n + 2 ) ! f ( 2 n + 2 ) ( x ) j = 0 ∏ n ( x − x j ) 2
这个公式与包含重复 n + 1 n+1 n + 1 2 n + 2 2n+2 2 n + 2
我们定义一组 2 n + 2 2n+2 2 n + 2
z 2 i = z 2 i + 1 = x i , 0 ≤ i ≤ n z_{2i} = z_{2i+1} = x_i, \quad 0 \le i \le n
z 2 i = z 2 i + 1 = x i , 0 ≤ i ≤ n
也就是新的 z z z x 0 , x 0 , x 1 , x 1 , x 2 , x 2 , … x_0, x_0, x_1, x_1, x_2, x_2, \ldots x 0 , x 0 , x 1 , x 1 , x 2 , x 2 , … f [ z i , … , z i + j ] f[z_i, \ldots, z_{i+j}] f [ z i , … , z i + j ]
f [ z 2 i , z 2 i + 1 ] = f ′ ( x i ) 而不是 f [ z 2 i + 1 ] − f [ z 2 i ] z 2 i + 1 − z 2 i f[z_{2i}, z_{2i+1}] = f'(x_i) \text{ 而不是 } \frac{f[z_{2i+1}] - f[z_{2i}]}{z_{2i+1} - z_{2i}}
f [ z 2 i , z 2 i + 1 ] = f ′ ( x i ) 而不是 z 2 i + 1 − z 2 i f [ z 2 i + 1 ] − f [ z 2 i ]
这种改变只影响差分表的第一列;其余的差分计算和之前一样进行。结果是赫米特插值多项式。
来看一个实际的例子,设我们有以下数据和它的导数值:
f ( − 1 ) = 2 , f ′ ( − 1 ) = − 1 , f ( 1 ) = 0 , f ′ ( 1 ) = 3 f(-1) = 2, \quad f'(-1) = -1, \quad f(1) = 0, \quad f'(1) = 3
f ( − 1 ) = 2 , f ′ ( − 1 ) = − 1 , f ( 1 ) = 0 , f ′ ( 1 ) = 3
差分表如下,导数值用方框标记,对角线条目像以前一样用于 p ( x ) p(x) p ( x )
i z i f [ z i ] f [ z i , z i − 1 ] ⋯ ⋯ 0 − 1 2 1 − 1 2 − 1 2 1 0 − 1 0 3 1 0 3 2 1 \begin{array}{c|c|ccccc}i&z_i&f[z_i]&f[z_i,z_{i-1}]&\cdots&\cdots\\0&-1&2\\1&-1&2&\boxed{\color{red}{-1}}\\2&1&0&-1&\color{red}{0}\\3&1&0&\boxed{3}&2&\color{red}{1}\\\end{array}
i 0 1 2 3 z i − 1 − 1 1 1 f [ z i ] 2 2 0 0 f [ z i , z i − 1 ] − 1 − 1 3 ⋯ 0 2 ⋯ 1
因此,我们得到赫米特插值多项式:
p ( x ) = 2 − ( x + 1 ) + 0 ⋅ ( x + 1 ) 2 + 1 ⋅ ( x + 1 ) 2 ( x − 1 ) p(x) = 2 - (x + 1) + 0 \cdot (x + 1)^2 + 1 \cdot (x + 1)^2(x - 1)
p ( x ) = 2 − ( x + 1 ) + 0 ⋅ ( x + 1 ) 2 + 1 ⋅ ( x + 1 ) 2 ( x − 1 )
通常,包含导数信息可以大幅提升插值的质量。虽然需要知道导数,但这通常是值得的。如果对于赫米特插值使用适当的点(例如 n + 1 n+1 n + 1 p 2 n + 1 p_{2n+1} p 2 n + 1 f f f
然而,即使赫米特插值能提供高精度的结果,高阶插值仍可能不是最佳选择。更常见的实践是分段方法,在点之间的区间内使用三次插值。这种方法在实际中广泛应用,特别是在需要连续导数的场合,如计算机图形学中的形状轮廓绘制。
三次样条插值是一种用于通过一组散点构造平滑曲线的方法,不仅在这些点上曲线的函数值与给定数据相吻合,而且在整个区间上曲线的一阶和二阶导数都连续,从而保证曲线的平滑过渡。
三次样条插值的核心是在每个相邻数据点间构造一个三次多项式。假设数据点为 ( x 0 , y 0 ) , ( x 1 , y 1 ) , … , ( x n , y n ) (x_0, y_0), (x_1, y_1), \ldots, (x_n, y_n) ( x 0 , y 0 ) , ( x 1 , y 1 ) , … , ( x n , y n ) ( x i , y i ) (x_i, y_i) ( x i , y i ) ( x i + 1 , y i + 1 ) (x_{i+1}, y_{i+1}) ( x i + 1 , y i + 1 ) S i ( x ) S_i(x) S i ( x ) i = 0 , 1 , … , n − 1 i = 0, 1, \ldots, n-1 i = 0 , 1 , … , n − 1 S i ( x ) S_i(x) S i ( x )
S i ( x ) = a i ( x − x i ) 3 + b i ( x − x i ) 2 + c i ( x − x i ) + d i S_i(x) = a_i(x - x_i)^3 + b_i(x - x_i)^2 + c_i(x - x_i) + d_i
S i ( x ) = a i ( x − x i ) 3 + b i ( x − x i ) 2 + c i ( x − x i ) + d i
这些三次多项式需要满足以下条件:
函数值匹配 :S i ( x i ) = y i S_i(x_i) = y_i S i ( x i ) = y i S i ( x i + 1 ) = y i + 1 S_i(x_{i+1}) = y_{i+1} S i ( x i + 1 ) = y i + 1 一阶导数连续 :S i − 1 ′ ( x i ) = S i ′ ( x i ) S_{i-1}'(x_i) = S_i'(x_i) S i − 1 ′ ( x i ) = S i ′ ( x i ) 二阶导数连续 :S i − 1 ′ ′ ( x i ) = S i ′ ′ ( x i ) S_{i-1}''(x_i) = S_i''(x_i) S i − 1 ′ ′ ( x i ) = S i ′ ′ ( x i )
通常还会对两端的样条函数施加自然边界条件或其他边界条件,以确保整个区间内曲线的平滑性。
示例:
对于给定的三个数据点 ( 1 , 2 ) (1, 2) ( 1 , 2 ) ( 2 , 3 ) (2, 3) ( 2 , 3 ) ( 3 , 5 ) (3, 5) ( 3 , 5 ) S 0 ( x ) S_0(x) S 0 ( x ) S 1 ( x ) S_1(x) S 1 ( x )
S 0 ( x ) = a 0 ( x − 1 ) 3 + b 0 ( x − 1 ) 2 + c 0 ( x − 1 ) + d 0 S_0(x) = a_0(x - 1)^3 + b_0(x - 1)^2 + c_0(x - 1) + d_0
S 0 ( x ) = a 0 ( x − 1 ) 3 + b 0 ( x − 1 ) 2 + c 0 ( x − 1 ) + d 0
S 1 ( x ) = a 1 ( x − 2 ) 3 + b 1 ( x − 2 ) 2 + c 1 ( x − 2 ) + d 1 S_1(x) = a_1(x - 2)^3 + b_1(x - 2)^2 + c_1(x - 2) + d_1
S 1 ( x ) = a 1 ( x − 2 ) 3 + b 1 ( x − 2 ) 2 + c 1 ( x − 2 ) + d 1
我们需要解决的线性方程组来自以下条件:
函数值条件 :
S 0 ( 1 ) = 2 S_0(1) = 2 S 0 ( 1 ) = 2 d 0 = 2 d_0 = 2 d 0 = 2 S 0 ( 2 ) = S 1 ( 2 ) = 3 S_0(2) = S_1(2) = 3 S 0 ( 2 ) = S 1 ( 2 ) = 3 a 0 + b 0 + c 0 + d 0 = 3 a_0 + b_0 + c_0 + d_0 = 3 a 0 + b 0 + c 0 + d 0 = 3 d 1 = 3 d_1 = 3 d 1 = 3 S 1 ( 3 ) = 5 S_1(3) = 5 S 1 ( 3 ) = 5 a 1 + b 1 + c 1 + d 1 = 5 a_1 + b_1 + c_1 + d_1 = 5 a 1 + b 1 + c 1 + d 1 = 5
一阶导数连续 :
S 0 ′ ( 2 ) = S 1 ′ ( 2 ) S_0'(2) = S_1'(2) S 0 ′ ( 2 ) = S 1 ′ ( 2 ) 3 a 0 + 2 b 0 + c 0 = 3 a 1 + c 1 3a_0 + 2b_0 + c_0 = 3a_1 + c_1 3 a 0 + 2 b 0 + c 0 = 3 a 1 + c 1
二阶导数连续 :
S 0 ′ ′ ( 2 ) = S 1 ′ ′ ( 2 ) S_0''(2) = S_1''(2) S 0 ′ ′ ( 2 ) = S 1 ′ ′ ( 2 ) 6 a 0 + 2 b 0 = 6 a 1 + 2 b 1 6a_0 + 2b_0 = 6a_1 + 2b_1 6 a 0 + 2 b 0 = 6 a 1 + 2 b 1
自然边界条件 (二阶导数为零):
S 0 ′ ′ ( 1 ) = 0 S_0''(1) = 0 S 0 ′ ′ ( 1 ) = 0 2 b 0 = 0 2b_0 = 0 2 b 0 = 0 S 1 ′ ′ ( 3 ) = 0 S_1''(3) = 0 S 1 ′ ′ ( 3 ) = 0 6 a 1 + 2 b 1 = 0 6a_1 + 2b_1 = 0 6 a 1 + 2 b 1 = 0
将这些条件转换为线性方程组,我们得到:
d 0 = 2 a 0 + b 0 + c 0 + d 0 = 3 a 1 + b 1 + c 1 + d 1 = 5 3 a 0 + 2 b 0 + c 0 = 3 a 1 + c 1 6 a 0 + 2 b 0 = 6 a 1 + 2 b 1 b 0 = 0 6 a 1 + 2 b 1 = 0 \begin{aligned}
d_0 &= 2 \\
a_0 + b_0 + c_0 + d_0 &= 3 \\
a_1 + b_1 + c_1 + d_1 &= 5 \\
3a_0 + 2b_0 + c_0 &= 3a_1 + c_1 \\
6a_0 + 2b_0 &= 6a_1 + 2b_1 \\
b_0 &= 0 \\
6a_1 + 2b_1 &= 0 \\
\end{aligned}
d 0 a 0 + b 0 + c 0 + d 0 a 1 + b 1 + c 1 + d 1 3 a 0 + 2 b 0 + c 0 6 a 0 + 2 b 0 b 0 6 a 1 + 2 b 1 = 2 = 3 = 5 = 3 a 1 + c 1 = 6 a 1 + 2 b 1 = 0 = 0
通过求解这个方程组,我们可以得到 a 0 , b 0 , c 0 , d 0 , a 1 , b 1 , c 1 , d 1 a_0, b_0, c_0, d_0, a_1, b_1, c_1, d_1 a 0 , b 0 , c 0 , d 0 , a 1 , b 1 , c 1 , d 1 S 0 ( x ) S_0(x) S 0 ( x ) S 1 ( x ) S_1(x) S 1 ( x )
最终的样条函数是由这些三次多项式在各自的区间上的表达式组合而成的,它们在整个插值区间上形成一条平滑且连续的曲线。三次样条插值以其出色的平滑性和较高的准确性,在曲线构造、图形设计以及工程计算等领域中有着广泛的应用。它能够生成既符合数据点,又光滑连续的曲线,是一种在实际中非常实用的插值方法。